Solving mathematical problems using computer-verifiable languages like Lean has significantly impacted the mathematical and computer science communities. State-of-the-art methods utilize a single Large Language Model (LLM) to generate complete proof or perform tree search, but they fail to balance these tasks. We propose MA-LoT: Model-CollAboration Lean-based Long Chain-of-Thought, a comprehensive framework for Lean4 theorem proving to solve this issue. It separates the cognition tasks of general NL for whole-proof generation and error analysis for proof correction using the model-collaboration method. We achieve this by structured interaction of the LLM and Lean4 verifier in Long CoT. To implement the framework, we propose the novel LoT-Transfer Learning training-inference pipeline, which enables the Long CoT thinking capability to LLMs without special data annotation. Extensive experiment shows that our framework achieves a 61.07% accuracy rate on the Lean4 version of the MiniF2F-Test dataset, largely outperforming DeepSeek-V3 (33.61%), single-model tree search (InternLM-Step-Prover, 50.70%), and whole-proof generation (Godel-Prover, 55.33%) baselines. Furthermore, our findings highlight the potential of combining Long CoT with formal verification for a more insightful generation in a broader perspective.
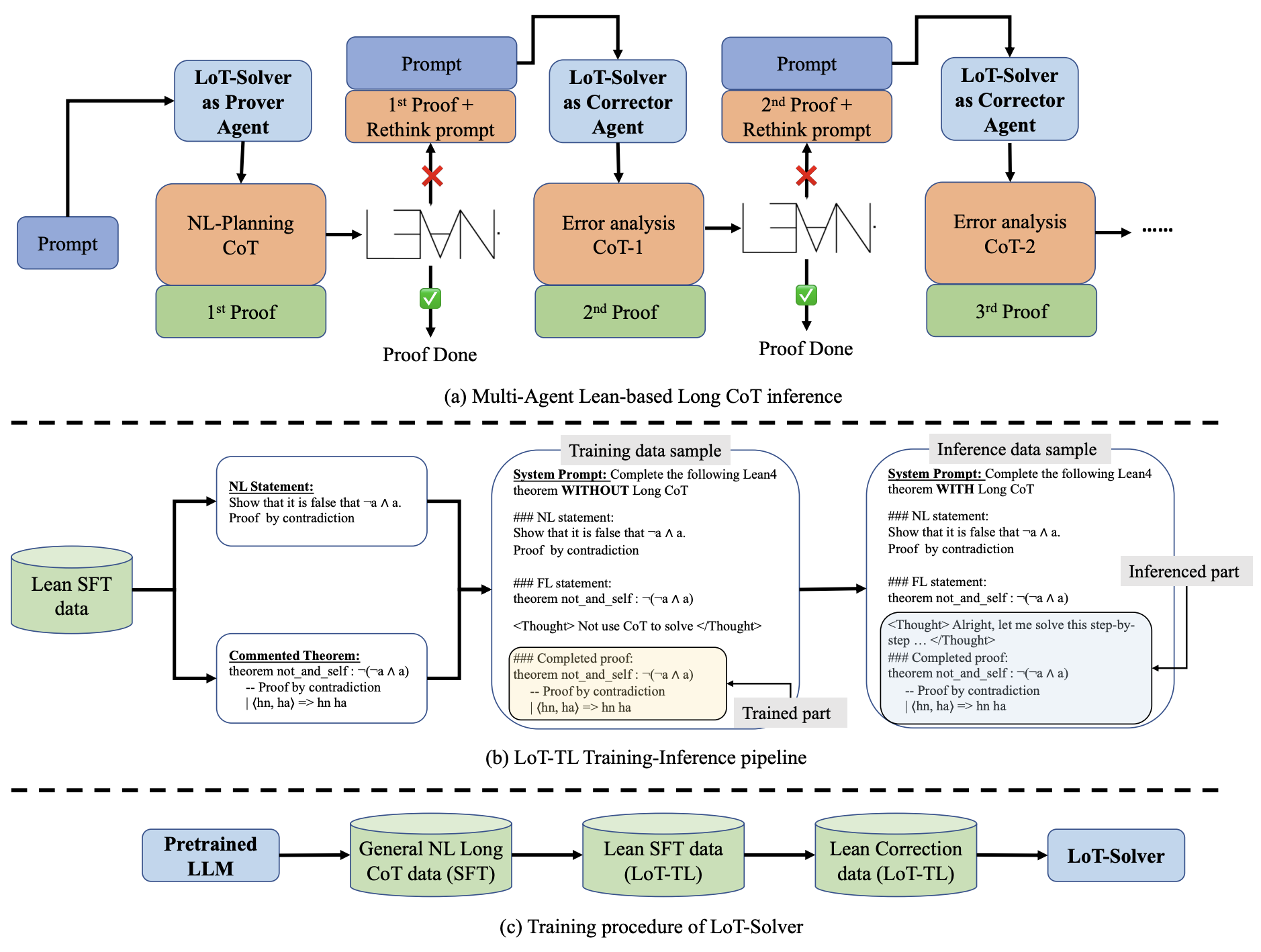
Fig.2 Overview of MA-LoT
This study proposes MA-LoT, a comprehensive Model-Collaboration Lean-based Long Chain-of-Thought method for enhancing formal theorem proving (details in Fig. 2). We achieve this by introducing a novel Lean-of-Thought Transfer-Learning (LoT-TL) training-inference pipeline that trains a model to possess field-specific Long CoT capabilities without the need for complex reinforcement learning (RL) or annotated Long CoT data.
In the training stage of LoT-TL, we first annotate a Natural Language–Formal Language (NL-FL) aligned supervised fine-tuning (SFT) dataset by writing formal language (FL) proofs for Lean-Workbook statements and corresponding natural language (NL) statements from the DeepSeek-Prover-V1 dataset. While writing Lean4 proofs for Lean-Workbook, we also collect incorrect attempts for each theorem and construct a dataset specifically for training a correction model. Subsequently, we use a general NL dataset to teach the LLM Long CoT capabilities, utilizing a system prompt to instruct the model to activate Long CoT mode. After that, we use the annotated SFT data to further train the model, instructing it via the system prompt to deactivate Long CoT, while preserving the Long CoT format through the use of placeholders. Finally, we train the model on the correction dataset using a similar method. After completing this training procedure, we obtain the LoT-Solver model, which serves as the base model for both the prover and corrector models.
The model-collaboration inference framework employs the LoT-Solver as the prover model, performing whole-proof generation based on the natural language and Lean4 statements of the given problem, guided by a system prompt and a Long CoT header instructing the model to use Long CoT analysis. Subsequently, the generated proofs are iteratively refined through a Long CoT-based correction mechanism. Specifically, the prover model analyzes and generates a proof, after which a separate verifier (also based on the LoT-Solver) checks and provides feedback, iteratively improving the solution. This collaborative loop continues until the proof is complete and correct.
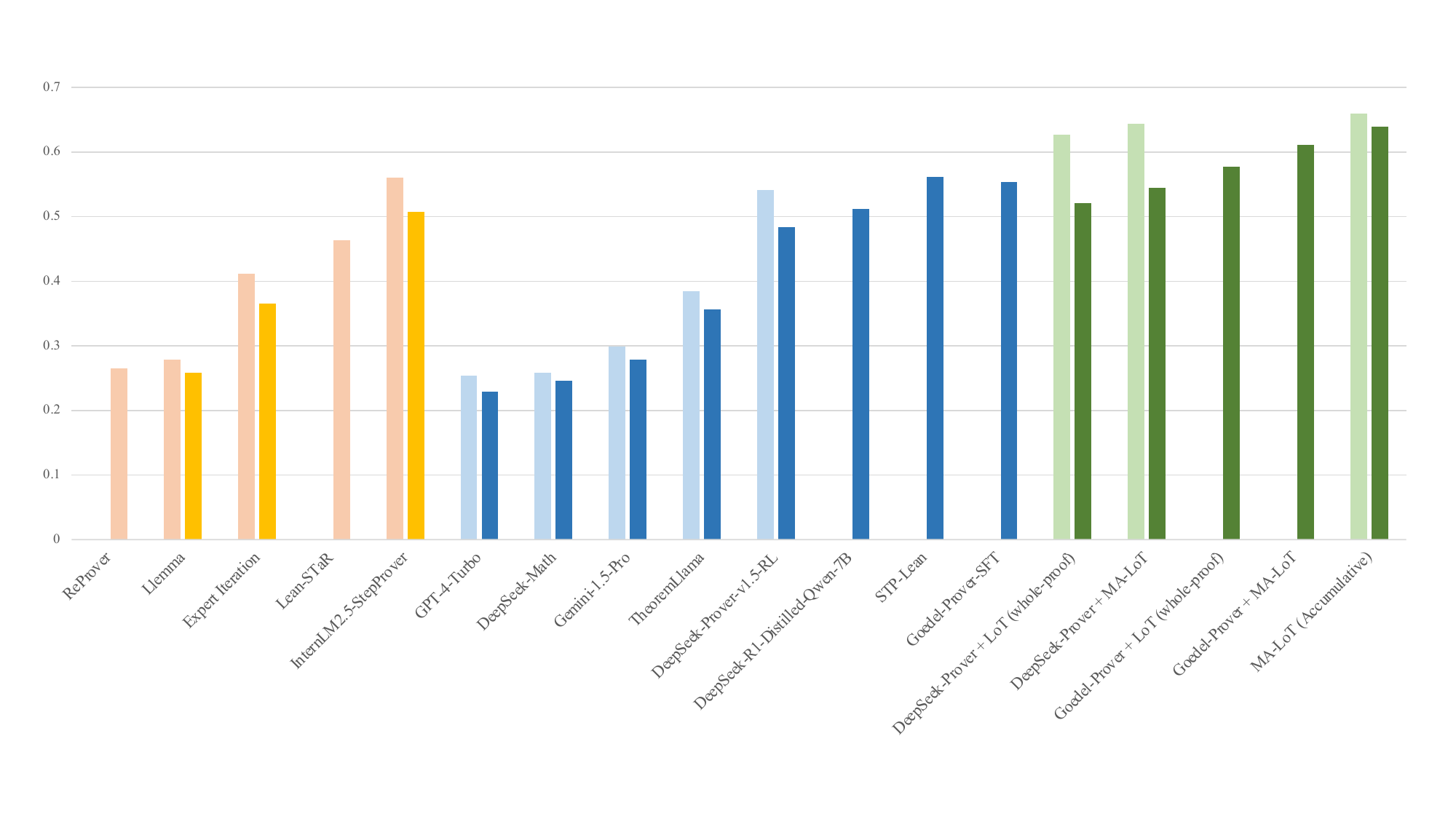
Following previous works, we measure the performance of the proposed framework by the MiniF2F-Test and Valid datasets. Both datasets contain 244 Lean4 statements, whose range varies from high-school competition questions to undergraduate-level theorem proofs. The dataset consists of problems from three sources: (1) 260 problems sampled from the MATH dataset. (2) 160 problems from high-school math competitions. (3) 168 manually crafted problems at the same difficulty level as (2).
| Method | Sample budget | MiniF2F-Valid | MiniF2F-Test |
|---|---|---|---|
| Tree-search methods | |||
| ReProver | pass@1 | - | 26.50% |
| Llemma | 1x32x100 | 27.90% | 25.80% |
| Expert Iteration | 8x8x512 | 41.20% | 36.60% |
| Lean-STaR | 64x1x50 | - | 46.30% |
| InternLM2.5-StepProver | 2x32x600 | 56.00% | 50.70% |
| Whole-proof generation methods | |||
| GPT-4-Turbo | pass@128 | 25.41% | 22.95% |
| DeepSeek-Math | pass@128 | 25.80% | 24.60% |
| Gemini-1.5-Pro | pass@128 | 29.92% | 27.87% |
| TheoremLlama | pass@128 | 38.52% | 35.66% |
| DeepSeek-Prover-v1.5-RL | pass@128 | 54.10% | 48.36% |
| DeepSeek-R1-Distilled-Qwen-7B | pass@32 | - | 51.23% |
| STP-Lean | pass@128 | - | 56.15% |
| Goedel-Prover-SFT | pass@32 | - | 55.33% |
| Our methods | |||
| DeepSeek-Prover + LoT (whole-proof) | pass@128 | 62.70% | 52.05% |
| DeepSeek-Prover + MA-LoT | 64 + 32x2 | 64.34% | 54.51% |
| Goedel-Prover + LoT (whole-proof) | pass@32 | - | 57.79% |
| Goedel-Prover + MA-LoT | 16 + 8x2 | - | 61.07% |
| MA-LoT | Accumulative | 65.98% | 63.93% |
The main experimental results of MA-LoT. Our results are presented as Base model + method. The LoT (whole-proof) indicates using the whole-proof results of our LoT-Solver model, and MA-LoT indicates the result of our whole pipeline. The sampling budget x + k*y in the MA-LoT indicates we forst perform x times of whole-proof writing using the prover and k rounds of correction using the corrector. In practice, one round of correction costs approximately half of the whole-proof generation budget, resulting in y = 1/2 x
| Method | Prover | 1 Round | 2 Round | 3 Round |
|---|---|---|---|---|
| DeepSeek-Prover + MA-LoT | 51.64% | 53.28% | 54.51% | 55.33% |
| Goedel-Prover + MA-LoT | 54.92% | 59.43% | 61.07% | 61.89% |
The experiment result of different rounds of correction is demonstrated in Table 2. The prover column demonstrates the pass@64 (or 16) result of the prover in the whole proof generation, while Round i indicates successive correction rounds. The results indicate that during the first three correction rounds, the corrector successfully corrected an average of 11.55% of theorems that the prover was unable to answer. The case study shows that most corrected proofs belong to IMO, AIME, and high-level MATH problems.
@misc{wang2025malot,
title={MA-LoT: Model-Collaboration Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving},
author={Ruida Wang and Rui Pan and Yuxin Li and Jipeng Zhang and Yizhen Jia and Shizhe Diao and Renjie Pi and Junjie Hu and Tong Zhang},
year={2025},
eprint={2503.03205},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.03205},
}